
Análisis de normalidad en IBM SPSS Statistics: Guía completa
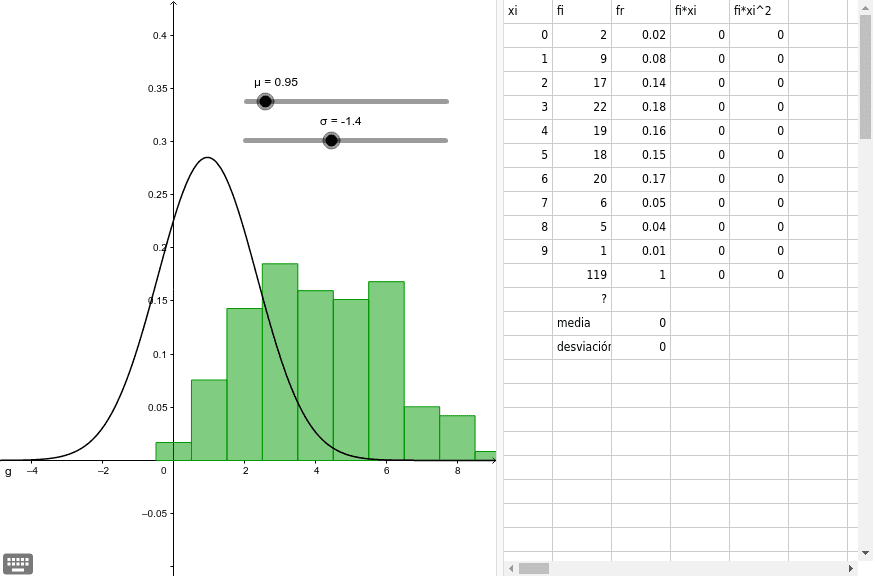
La normalidad es un concepto fundamental en la estadística y se refiere a la distribución de los datos en una muestra o población. En el análisis de datos, es importante determinar si los datos siguen una distribución normal para poder aplicar ciertos métodos estadísticos. IBM SPSS Statistics es una herramienta de análisis estadístico ampliamente utilizada en el campo de la investigación y ofrece diversas opciones para evaluar la normalidad de los datos.
Exploraremos en detalle cómo realizar un análisis de normalidad en IBM SPSS Statistics. Veremos los pasos necesarios para verificar la normalidad de los datos, así como las diferentes pruebas y gráficos disponibles en el software. Además, examinaremos la interpretación de los resultados y discutiremos algunas consideraciones importantes al analizar la normalidad en SPSS.
- Por qué es importante realizar un análisis de normalidad en los datos
- Cuáles son los supuestos del análisis de normalidad en SPSS
- Cómo puedo comprobar la normalidad de mis datos en SPSS
- Qué gráficos puedo utilizar para visualizar la normalidad de mis datos en SPSS
- Cuáles son las pruebas estadísticas más comunes para evaluar la normalidad en SPSS
- Qué pasa si mis datos no siguen una distribución normal en SPSS
- Existen técnicas de transformación de datos para mejorar la normalidad en SPSS
- Cómo interpretar los resultados del análisis de normalidad en SPSS
- Es posible realizar un análisis de normalidad en SPSS con datos categóricos
- Cuáles son las alternativas al análisis de normalidad en SPSS si mis datos no son normales
-
Preguntas frecuentes (FAQ)
- 1. ¿Qué es el análisis de normalidad?
- 2. ¿Por qué es importante realizar un análisis de normalidad?
- 3. ¿Cómo puedo realizar un análisis de normalidad en IBM SPSS Statistics?
- 4. ¿Cuál es la interpretación de los resultados de un análisis de normalidad?
- 5. ¿Qué hacer si los datos no siguen una distribución normal?
Por qué es importante realizar un análisis de normalidad en los datos
Realizar un análisis de normalidad en los datos es fundamental para garantizar la validez de los resultados obtenidos en un estudio o investigación. La normalidad de los datos es un supuesto básico en muchos análisis estadísticos, ya que permite hacer inferencias y estimaciones más precisas.
La normalidad se refiere a la distribución de los datos en una población. Una distribución normal se caracteriza por ser simétrica, con la mayor parte de los datos concentrados en el centro y las colas distribuidas de manera equitativa a ambos lados.
La violación de este supuesto puede comprometer la validez de los resultados, ya que muchos métodos estadísticos se basan en la suposición de normalidad. Por lo tanto, es fundamental realizar un análisis de normalidad para verificar si los datos siguen una distribución normal.
Existen diferentes métodos para evaluar la normalidad de los datos, como el test de Shapiro-Wilk, el test de Kolmogorov-Smirnov o el test de Anderson-Darling. Estos tests se utilizan para determinar si la distribución de los datos se desvía significativamente de la normalidad.
Realizar un análisis de normalidad es esencial para garantizar la confiabilidad y validez de los resultados estadísticos. Si los datos no siguen una distribución normal, es necesario tomar precauciones al interpretar los resultados y considerar el uso de métodos estadísticos alternativos.
Cuáles son los supuestos del análisis de normalidad en SPSS
El análisis de normalidad es una herramienta fundamental en la estadística para evaluar si una variable sigue una distribución normal. En IBM SPSS Statistics, existen diferentes pruebas y gráficos que nos ayudan a analizar esta normalidad.
Los supuestos del análisis de normalidad en SPSS incluyen:
1. Normalidad univariada
El supuesto de normalidad univariada implica que cada variable a analizar debe tener una distribución normal. Esto se puede evaluar mediante la prueba de Kolmogorov-Smirnov o la prueba de Shapiro-Wilk en SPSS.
2. Linealidad
El supuesto de linealidad establece que la relación entre las variables debe ser lineal. Esto se puede verificar utilizando gráficos de dispersión en SPSS.
3. Independencia
El supuesto de independencia indica que las observaciones deben ser independientes entre sí. Si hay dependencia en los datos, los resultados del análisis de normalidad pueden estar sesgados. Se debe tener cuidado al analizar datos longitudinales o de series temporales.
4. Homocedasticidad
El supuesto de homocedasticidad implica que la varianza de los errores debe ser constante en todos los niveles de las variables predictoras. Se puede verificar utilizando gráficos de residuos en SPSS.
El análisis de normalidad en SPSS se basa en supuestos importantes que deben ser evaluados antes de realizar cualquier análisis estadístico. SPSS proporciona las herramientas necesarias para evaluar la normalidad de las variables y garantizar la validez de los resultados obtenidos.
Cómo puedo comprobar la normalidad de mis datos en SPSS
Comprobar la normalidad de los datos es esencial para muchos análisis estadísticos. En IBM SPSS Statistics, existen varias formas de realizar esta verificación. Una opción es utilizar pruebas estadísticas como la prueba de Shapiro-Wilk o la prueba de Kolmogorov-Smirnov. Estas pruebas evalúan si los datos siguen una distribución normal.
Para realizar la prueba de Shapiro-Wilk en SPSS, simplemente debes seleccionar la opción "Analizar" en la barra de menú, luego seleccionar "Pruebas no paramétricas" y finalmente elegir la opción "Prueba de normalidad de Shapiro-Wilk". A continuación, debes seleccionar las variables que deseas analizar y hacer clic en "Aceptar".
Por otro lado, si prefieres utilizar la prueba de Kolmogorov-Smirnov, debes seguir los mismos pasos anteriores pero seleccionar la opción "Prueba de normalidad de Kolmogorov-Smirnov". Recuerda que estos métodos son solo dos de las opciones disponibles en SPSS para comprobar la normalidad de los datos.
Además de las pruebas estadísticas, SPSS también te ofrece la posibilidad de visualizar gráficamente los datos para evaluar su normalidad. Puedes utilizar histogramas, gráficos de probabilidad normal o gráficos Q-Q para analizar la distribución de tus datos.
Qué gráficos puedo utilizar para visualizar la normalidad de mis datos en SPSS
En IBM SPSS Statistics, existen varias opciones de gráficos que te permiten visualizar la normalidad de tus datos. Estas herramientas son útiles para evaluar si tus datos siguen una distribución normal, lo cual es un supuesto común en muchos análisis estadísticos.
Uno de los gráficos más utilizados es el histograma, el cual muestra la distribución de tus datos en forma de barras. Si los datos siguen una distribución normal, el histograma debería tener una forma de campana simétrica. Sin embargo, ten en cuenta que el aspecto del histograma puede variar dependiendo del tamaño de la muestra y el número de intervalos que especificas.
Otra opción es el gráfico Q-Q, que compara los cuantiles esperados de una distribución normal con los cuantiles reales de tus datos. Si los puntos en el gráfico caen aproximadamente en una línea recta, esto sugiere que tus datos siguen una distribución normal. Por otro lado, si los puntos se desvían mucho de la línea recta, esto indica que tus datos no son normales.
Cuáles son las pruebas estadísticas más comunes para evaluar la normalidad en SPSS
En IBM SPSS Statistics, existen varias pruebas estadísticas que se utilizan comúnmente para evaluar la normalidad de los datos. Estas pruebas son fundamentales para determinar si una distribución de datos sigue una distribución normal o si difiere significativamente de ella.
La prueba de normalidad de Shapiro-Wilk es una de las más utilizadas en SPSS. Esta prueba calcula el estadístico W y su correspondiente p-valor, que indica la probabilidad de que los datos provengan de una distribución normal. Si el p-valor es mayor que el nivel de significancia establecido (generalmente 0.05), se acepta la hipótesis nula de normalidad.
Otra prueba común es la prueba de normalidad de Kolmogorov-Smirnov. Esta prueba compara la distribución de los datos con la distribución normal teórica utilizando la distancia máxima entre las dos funciones de distribución acumulada. Al igual que la prueba de Shapiro-Wilk, se evalúa el p-valor para determinar la normalidad de los datos.
Además de estas pruebas, SPSS también ofrece la prueba de normalidad de Lilliefors, que es una variante de la prueba de Kolmogorov-Smirnov. Esta prueba tiene en cuenta el tamaño de la muestra y proporciona una corrección más precisa en comparación con la prueba original.
Es importante destacar que ninguna de estas pruebas garantiza la normalidad absoluta de los datos, ya que todas ellas se basan en una muestra y están sujetas a errores. Sin embargo, pueden proporcionar una indicación útil sobre la distribución de los datos y ayudar a tomar decisiones informadas en el análisis estadístico.
Qué pasa si mis datos no siguen una distribución normal en SPSS
Una de las suposiciones fundamentales en muchos análisis estadísticos es que los datos siguen una distribución normal. Sin embargo, en la práctica, es común encontrarse con conjuntos de datos que no siguen esta distribución. En IBM SPSS Statistics, cuando los datos no son normales, existen varias opciones a considerar.
Transformación de datos
Una estrategia común para abordar la falta de normalidad en los datos es transformarlos. Esto implica aplicar una función matemática a los datos para cambiar su distribución y hacerla más cercana a una distribución normal. En SPSS, puedes utilizar varias transformaciones, como la transformación logarítmica o la transformación de raíz cuadrada.
Pruebas no paramétricas
Si los datos no se pueden transformar adecuadamente, otra opción es utilizar pruebas estadísticas no paramétricas. Estas pruebas no requieren suposiciones sobre la distribución de los datos y son más robustas frente a la falta de normalidad. En SPSS, puedes realizar pruebas no paramétricas como la prueba de Mann-Whitney U o la prueba de Kruskal-Wallis.
Análisis robusto
Otra alternativa es utilizar métodos de análisis robustos que sean menos sensibles a los valores atípicos o a la falta de normalidad. En SPSS, puedes emplear técnicas como la regresión robusta o los métodos de estimación M y MM.
Si tus datos no siguen una distribución normal en IBM SPSS Statistics, tienes varias opciones para abordar este problema. Puedes transformar los datos, emplear pruebas no paramétricas o utilizar análisis robustos. La elección dependerá de la naturaleza de tus datos y los objetivos de tu análisis. Recuerda que es importante evaluar la normalidad de los datos y seleccionar la estrategia adecuada para obtener resultados válidos y confiables.
Existen técnicas de transformación de datos para mejorar la normalidad en SPSS
La normalidad de los datos es una suposición fundamental en muchos análisis estadísticos. Sin embargo, es común encontrar conjuntos de datos que no siguen una distribución normal. Afortunadamente, IBM SPSS Statistics proporciona varias técnicas de transformación de datos que pueden ayudar a mejorar la normalidad de los datos y, por lo tanto, garantizar la validez de los análisis posteriores.
Uno de los métodos más utilizados para transformar datos no normales en SPSS es la transformación logarítmica. Esta técnica se basa en la suposición de que los datos siguen una distribución log-normal y se utiliza principalmente cuando los datos están sesgados positivamente.
Otra técnica comúnmente utilizada es la transformación de raíz cuadrada. Esta transformación se aplica a los datos cuando se sospecha de sesgo negativo. La transformación de raíz cuadrada es especialmente útil cuando se trabaja con datos que representan conteos o frecuencias, como el número de ventas o el número de eventos ocurridos.
Además de estas técnicas de transformación básicas, SPSS también ofrece otras opciones más avanzadas, como la transformación de Box-Cox. Esta técnica es útil cuando la relación entre la varianza y el valor medio no es constante y proporciona una transformación óptima para mejorar la normalidad de los datos.
Si tus datos no siguen una distribución normal, no te preocupes. IBM SPSS Statistics ofrece una amplia gama de técnicas de transformación de datos que te permitirán mejorar la normalidad y garantizar la validez de tus análisis estadísticos. Explora estas opciones y elige la que mejor se adapte a tu conjunto de datos y tus objetivos de investigación.
Cómo interpretar los resultados del análisis de normalidad en SPSS
El análisis de normalidad es una parte importante en la estadística descriptiva y es fundamental para muchas pruebas de hipótesis. En IBM SPSS Statistics, se realiza el análisis de normalidad para evaluar si los datos de una muestra siguen una distribución normal. Esta guía completa te enseñará cómo interpretar los resultados de este análisis.
¿Qué es la distribución normal?
La distribución normal, también conocida como distribución de Gauss o campana de Gauss, es una distribución simétrica que se caracteriza por tener la media, mediana y moda coincidiendo en el mismo punto central. Es una distribución muy común en la naturaleza y en muchos fenómenos sociales y científicos.
Importancia del análisis de normalidad
El análisis de normalidad es relevante porque muchos métodos estadísticos se basan en la suposición de que los datos siguen una distribución normal. Al identificar si los datos de una muestra se ajustan a una distribución normal, podemos tomar decisiones más confiables al realizar pruebas de hipótesis, intervalos de confianza y análisis de regresión.
Qué indica el análisis de normalidad en SPSS
En SPSS, el análisis de normalidad se realiza mediante el cálculo del coeficiente de asimetría (skewness) y el coeficiente de curtosis (kurtosis) de los datos. El coeficiente de asimetría mide la asimetría de la distribución y el coeficiente de curtosis mide la forma de la distribución.
Si el coeficiente de asimetría es cercano a cero, indica que los datos están aproximadamente simétricamente distribuidos. Un valor negativo indica una asimetría hacia la izquierda y un valor positivo indica una asimetría hacia la derecha.
Por otro lado, si el coeficiente de curtosis es cercano a cero, indica que la distribución tiene una forma similar a la distribución normal estándar (curva de campana). Un valor negativo indica una distribución menos puntiaguda (aplana) y un valor positivo indica una distribución más puntiaguda (picuda).
Interpretación de los resultados
Al interpretar los resultados del análisis de normalidad en SPSS, debemos prestar atención tanto al coeficiente de asimetría como al coeficiente de curtosis. Si ambos coeficientes están cerca de cero, podemos asumir que los datos siguen una distribución normal.
Si el coeficiente de asimetría está significativamente alejado de cero (por ejemplo, mayor a 2 o menor a -2), indica una fuerte asimetría en la distribución. En este caso, los datos pueden no seguir una distribución normal y se debe considerar utilizar métodos estadísticos alternativos.
Del mismo modo, si el coeficiente de curtosis está significativamente alejado de cero (por ejemplo, mayor a 2 o menor a -2), indica una forma de distribución muy diferente a la distribución normal estándar. Esto también sugiere que los datos pueden no seguir una distribución normal y se debe considerar utilizar métodos estadísticos alternativos.
El análisis de normalidad en IBM SPSS Statistics es una herramienta importante para evaluar si los datos siguen una distribución normal. Interpretar correctamente los resultados nos permite tomar decisiones más confiables en nuestras pruebas de hipótesis y análisis estadísticos. Recuerda que si los coeficientes de asimetría y curtosis están cerca de cero, los datos se ajustan a una distribución normal, pero si están alejados de cero, se deben considerar métodos alternativos.
Es posible realizar un análisis de normalidad en SPSS con datos categóricos
En IBM SPSS Statistics, es posible realizar un análisis de normalidad incluso cuando se trabajan con datos categóricos. Aunque el análisis de normalidad generalmente se aplica a datos continuos, SPSS ofrece diferentes opciones para evaluar la distribución de variables categóricas.
Una de las formas más comunes de analizar la normalidad en datos categóricos es a través del test chi-cuadrado de bondad de ajuste. Este test compara la distribución observada de una variable categórica con una distribución teórica esperada, como una distribución uniforme o una distribución normal.
Para realizar este análisis en SPSS, es necesario utilizar el módulo "Exact Tests" que se encuentra en la sección "Analyze" del programa. A través de esta opción, se puede seleccionar el test chi-cuadrado de bondad de ajuste y especificar las variables categóricas a analizar.
Es importante tener en cuenta que el análisis de normalidad en datos categóricos tiene limitaciones y no proporciona una medida exacta de la normalidad. Sin embargo, puede ser útil para evaluar la similitud de una distribución categórica con una distribución teórica esperada.
Cuáles son las alternativas al análisis de normalidad en SPSS si mis datos no son normales
Si tus datos no siguen una distribución normal y necesitas realizar análisis estadísticos, no te preocupes, hay alternativas disponibles en IBM SPSS Statistics. Una opción es utilizar pruebas no paramétricas, que no asumen la normalidad en los datos. Algunas pruebas no paramétricas comunes incluyen la Prueba de Mann-Whitney para comparar dos grupos y la Prueba de Kruskal-Wallis para comparar más de dos grupos. Estas pruebas no se basan en la distribución de los datos y son adecuadas cuando tienes datos no normales.
Otra opción es transformar los datos en una escala diferente para lograr una distribución más cercana a la normal. Por ejemplo, puedes aplicar la transformación de logaritmo o una transformación de raíz cuadrada a tus datos. Después de aplicar la transformación, puedes realizar análisis estadísticos en los datos transformados.
Además, puedes utilizar métodos robustos que son menos sensibles a las desviaciones de la distribución normal. Estos métodos utilizan estimadores robustos en lugar de los estimadores de máxima verosimilitud utilizados en los análisis paramétricos. Estos estimadores son menos afectados por los valores atípicos y pueden proporcionar resultados más confiables en presencia de datos no normales.
Si tus datos no son normales, puedes utilizar pruebas no paramétricas, transformar tus datos en una escala diferente o utilizar métodos robustos. Estas alternativas te permitirán realizar análisis estadísticos en SPSS, incluso cuando tus datos no sigan una distribución normal.
Preguntas frecuentes (FAQ)
1. ¿Qué es el análisis de normalidad?
El análisis de normalidad es una técnica estadística utilizada para determinar si una variable sigue o no una distribución normal.
2. ¿Por qué es importante realizar un análisis de normalidad?
Realizar un análisis de normalidad es importante porque muchas técnicas estadísticas, como la prueba t de Student o el análisis de varianza, asumen que los datos siguen una distribución normal. Si los datos no siguen una distribución normal, los resultados de estas pruebas pueden ser incorrectos o sesgados.
3. ¿Cómo puedo realizar un análisis de normalidad en IBM SPSS Statistics?
En IBM SPSS Statistics, puedes realizar un análisis de normalidad utilizando la prueba de Kolmogorov-Smirnov o la prueba de Shapiro-Wilk. Estas pruebas te permiten determinar si los datos siguen una distribución normal o no.
4. ¿Cuál es la interpretación de los resultados de un análisis de normalidad?
Si el valor de significancia (p-valor) asociado a la prueba es mayor que el nivel de significancia establecido (por ejemplo, 0.05), entonces se acepta la hipótesis nula y se concluye que los datos siguen una distribución normal. Si el p-valor es menor que el nivel de significancia, entonces se rechaza la hipótesis nula y se concluye que los datos no siguen una distribución normal.
5. ¿Qué hacer si los datos no siguen una distribución normal?
Si los datos no siguen una distribución normal, es posible que sea necesario utilizar técnicas estadísticas no paramétricas o transformar los datos para cumplir con el supuesto de normalidad. Consultar con un estadístico o experto en la materia puede ser útil para determinar la mejor forma de analizar los datos en esta situación.
Entradas relacionadas